
One sample t test
A one sample t test compares the mean with a hypothetical value. In most cases, the hypothetical value comes from theory. For example, if you express your data as 'percent of control', you can test whether the average differs significantly from 100. The hypothetical value can also come from previous data. For example, compare whether the mean systolic blood pressure differs from 135, a value determined in a previous study.
Learn more about the one sample t test
In this article you will learn the requirements and assumptions of a one sample t test, how to format and interpret the results of a one sample t test, and when to use different types of t tests.
One sample t test: Overview
The one sample t test, also referred to as a single sample t test, is a statistical hypothesis test used to determine whether the mean calculated from sample data collected from a single group is different from a designated value specified by the researcher. This designated value does not come from the data itself, but is an external value chosen for scientific reasons. Often, this designated value is a mean previously established in a population, a standard value of interest, or a mean concluded from other studies. Like all hypothesis testing, the one sample t test determines if there is enough evidence reject the null hypothesis (H0) in favor of an alternative hypothesis (H1). The null hypothesis for a one sample t test can be stated as: "The population mean equals the specified mean value." The alternative hypothesis for a one sample t test can be stated as: "The population mean is different from the specified mean value."
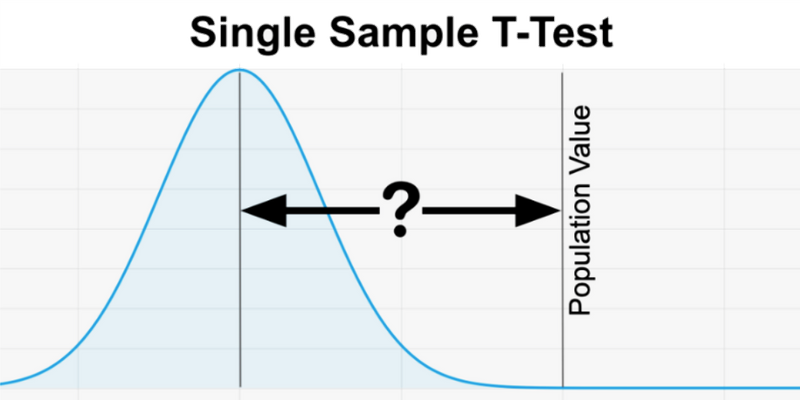
The one sample t test differs from most statistical hypothesis tests because it does not compare two separate groups or look at a relationship between two variables. It is a straightforward comparison between data gathered on a single variable from one population and a specified value defined by the researcher.
The one sample t test can be used to look for a difference in only one direction from the standard value (a one-tailed t test) or can be used to look for a difference in either direction from the standard value (a two-tailed t test).
Requirements and Assumptions for a one sample t test
A one sample t test should be used only when data has been collected on one variable for a single population and there is no comparison being made between groups.
For a valid one sample t test analysis, data values must be all of the following:
-
Independent (values are not related to one another):
The one sample t test assumes that all "errors" in the data are independent. The term "error" refers to the difference between each value and the group mean. The results of a t test only make sense when the scatter is random - that whatever factor caused a value to be too high or too low affects only that one value. Prism cannot test this assumption, but there are graphical ways to explore data to verify this assumption is met.
-
Continuous measurements
A t test is only appropriate to apply in situations where data represent variables that are continuous measurements. As they rely on the calculation of a mean value, variables that are categorical should not be analyzed using a t test.
-
Obtained from a random sample of the population
The results of a t test should be based on a random sample and only be generalized to the larger population from which samples were drawn.
-
Normally distributed in the population (data should resemble a bell-shaped curve when plotted graphically)
As with all parametric hypothesis testing, the one sample t test assumes that you have sampled your data from a population that follows a normal (or Gaussian) distribution. While this assumption is not as important with large samples, it is important with small sample sizes, especially less than 10. If your data do not come from a Gaussian distribution, there are three options to accommodate this. One option is to transform the values to make the distribution more Gaussian, perhaps by transforming all values to their reciprocals or logarithms. Another choice is to use the Wilcoxon signed rank nonparametric test instead of the t test. A final option is to use the t test anyway, knowing that the t test is fairly robust to departures from a Gaussian distribution with large samples.
How to format a one sample t test
Ideally, data for a one sample t test should be collected and entered as a single column from which a mean value can be easily calculated. If data is entered on a table with multiple subcolumns, Prism requires one of the following choices to be selected to perform the analysis:
- Each subcolumn of data can be analyzed separately
- An average of the values in the columns across each row can be calculated, and the analysis conducted on this new stack of means, or
- All values in all columns can be treated as one sample of data (paying no attention to which row or column any values are in).
How the one sample t test calculator works
Prism calculates the t ratio by dividing the difference between the actual and hypothetical means by the standard error of the actual mean. The equation is written as follows, where x is the calculated mean, μ is the hypothetical mean (specified value), S is the standard deviation of the sample, and n is the sample size:
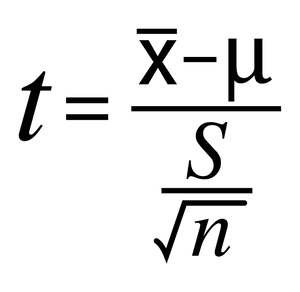
A p value is computed based on the calculated t ratio and the numbers of degrees of freedom present (which equals sample size minus 1). The one sample t test calculator assumes it is a two-tailed one sample t test, meaning you are testing for a difference in either direction from the specified value.
How to interpret results of a one sample t test
As discussed, a one sample t test compares the mean of a single column of numbers against a hypothetical mean. This hypothetical mean can be based upon a specific standard or other external prediction. The test produces a P value which requires careful interpretation.
The p value answers this question: If the data were sampled from a Gaussian population with a mean equal to the hypothetical value you entered, what is the chance of randomly selecting N data points and finding a mean as far (or further) from the hypothetical value as observed here?
If the p value is large (usually defined to mean greater than 0.05), the data do not give you any reason to conclude that the population mean differs from the designated value to which it has been compared. This is not the same as saying that the true mean equals the hypothetical value, but rather states that there is no evidence of a difference. Thus, we cannot reject the null hypothesis (H0).
If the p value is small (usually defined to mean less than or equal to 0.05), then it is unlikely that the discrepancy observed between the sample mean and hypothetical mean is due to a coincidence arising from random sampling. There is evidence to reject the idea that the difference is coincidental and conclude instead that the population has a mean that is different from the hypothetical value to which it has been compared. The difference is statistically significant, and the null hypothesis is therefore rejected.
If the null hypothesis is rejected, the question of whether the difference is scientifically important still remains. The confidence interval can be a useful tool in answering this question. Prism reports the 95% confidence interval for the difference between the actual and hypothetical mean. In interpreting these results, one can be 95% sure that this range includes the true difference. It requires scientific judgment to determine if this difference is truly meaningful.
Performing t tests? We can help.
Sign up for more information on how to perform t tests and other common statistical analyses.
When to use different types of t tests
There are three types of t tests which can be used for hypothesis testing:
- One sample t test
- Independent two-sample (or unpaired) t test
- Paired sample t test
As described, a one sample t test should be used only when data has been collected on one variable for a single population and there is no comparison being made between groups. It only applies when the mean value for data is intended to be compared to a fixed and defined number.
In most cases involving data analysis, however, there are multiple groups of data either representing different populations being compared, or the same population being compared at different times or conditions. For these situations, it is not appropriate to use a one sample t test. Other types of t tests are appropriate for these specific circumstances:
Independent Two-Sample t test (Unpaired t test)
The independent sample t test, also referred to as the unpaired t test, is used to compare the means of two different samples. The independent two-sample t test comes in two different forms:
- the standard Student's t test, which assumes that the variance of the two groups are equal.
- the Welch's t test, which is less restrictive compared to the original Student's test. This is the test where you do not assume that the variance is the same in the two groups, which results in fractional degrees of freedom.
The two methods give very similar results when the sample sizes are equal and the variances are similar.
Paired Sample t test
The paired sample t test is used to compare the means of two related groups of samples. Put into other words, it is used in a situation where you have two values (i.e., a pair of values) for the same group of samples. Often these two values are measured from the same samples either at two different times, under two different conditions, or after a specific intervention.
You can perform multiple independent two-sample comparison tests simultaneously in Prism. Select from parametric and nonparametric tests and specify if the data are unpaired or paired. Try performing a t test with a 30-day free trial of Prism.
Watch this video to learn how to choose between a paired and unpaired t test.
Example of how to apply the appropriate t test
"Alkaline" labeled bottled drinking water has become fashionable over the past several years. Imagine we have collected a random sample of 30 bottles of "alkaline" drinking water from a number of different stores to represent the population of "alkaline" bottled water for a particular brand available to the general consumer. The labels on each of the bottles claim that the pH of the "alkaline" water is 8.5. A laboratory then proceeds to measure the exact pH of the water in each bottle.
Table 1: pH of water in random sample of "alkaline bottled water"
pH in bottles of water
8.21
8.41
8.48
8.52
8.58
8.63
8.28
8.42
8.50
8.52
8.59
8.64
8.35
8.43
8.50
8.55
8.60
8.68
8.36
8.45
8.51
8.56
8.62
8.69
8.38
8.46
8.52
8.56
8.62
8.76
If you look at the table above, you see that some bottles have a pH measured to be lower than 8.5, while other bottles have a pH measured to be higher. What can the data tell us about the actual pH levels found in this brand of "alkaline" water bottles marketed to the public as having a pH of 8.5? Statistical hypothesis testing provides a sound method to evaluate this question. Which specific test to use, however, depends on the specific question being asked.
Is a t test appropriate to apply to this data?
Let's start by asking: Is a t test an appropriate method to analyze this set of pH data? The following list reviews the requirements and assumptions for using a t test:
- Independent sampling: In an independent sample t test, the data values are independent. The pH of one bottle of water does not depend on the pH of any other water bottle. (An example of dependent values would be if you collected water bottles from a single production lot. A sample from a single lot is representative only of that lot, not of alkaline bottled water in general).
- Continuous variable: The data values are pH levels, which are numerical measurements that are continuous.
- Random sample: We assume the water bottles are a simple random sample from the population of "alkaline" water bottles produced by this brand as they are a mix of many production lots.
- Normal distribution: We assume the population from which we collected our samples has pH levels that are normally distributed. To verify this, we should visualize the data graphically. The figure below shows a histogram for the pH measurements of the water bottles. From a quick look at the histogram, we see that there are no unusual points, or outliers. The data look roughly bell-shaped, so our assumption of a normal distribution seems reasonable. The QQ plot can also be used to graphically assess normality and is the preferred choice when the sample size is small.
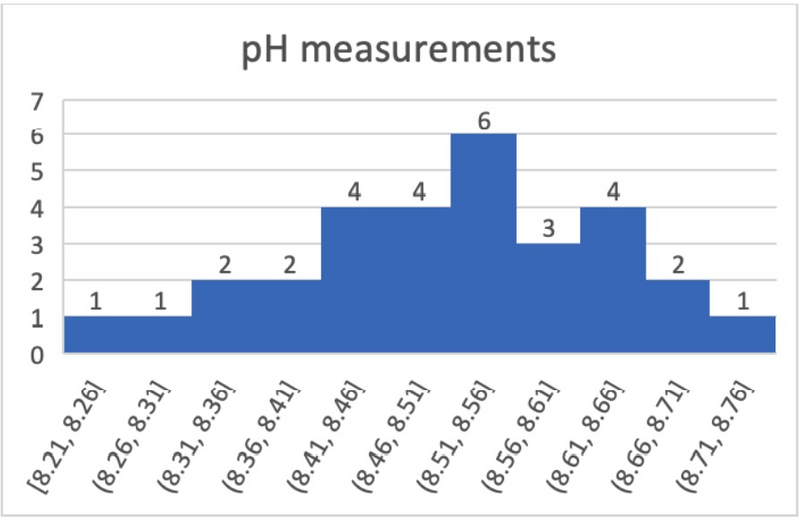
Based upon these features and assumptions being met, we can conclude that a t test is an appropriate method to be applied to this set of data.
Which t test is appropriate to use?
The next decision is which t test to apply, and this depends on the exact question we would like our analysis to answer. This example illustrates how each type of t test could be chosen for a specific analysis, and why the one sample t test is the correct choice to determine if the measured pH of the bottled water samples match the advertised pH of 8.5.
We could be interested in determining whether a certain characteristic of a water bottle is associated with having a higher or lower pH, such as whether bottles are glass or plastic. For this questions, we would effectively be dividing the bottles into 2 separate groups and comparing the means of the pH between the 2 groups. For this analysis, we would elect to use a two sample t test because we are comparing the means of two independent groups.
We could also be interested in learning if pH is affected by a water bottle being opened and exposed to the air for a week. In this case, each original sample would be tested for pH level after a week had elapsed and the water had been exposed to the air, creating a second set of sample data. To evaluate whether this exposure affected pH, we would again be comparing two different groups of data, but this time the data are in paired samples each having an original pH measurement and a second measurement from after the week of exposure to the open air. For this analysis, it is appropriate to use a paired t test so that data for each bottle is assembled in rows, and the change in pH is considered bottle by bottle.
Returning to the original question we set out to answer-whether bottled water that is advertised to have a pH of 8.5 actually meets this claim-it is now clear that neither an independent two sample t test or a paired t test would be appropriate. In this case, all 30 pH measurements are sampled from one group representing bottled drinking water labeled "alkaline" available to the general consumer. We wish to compare this measured mean with an expected advertised value of 8.5. This is the exact situation for which one should employ a one sample t test!
From a quick look at the descriptive statistics, we see that the mean of the sample measurements is 8.513, slightly above 8.5. Does this average from our sample of 30 bottles validate the advertised claim of pH 8.5? By applying Prism's one sample t test analysis to this data set, we will get results by which we can evaluate whether the null hypothesis (that there is no difference between the mean pH level in the water bottles and the pH level advertised on the bottles) should be accepted or rejected.
How to Perform a One Sample T Test in Prism
In prior versions of Prism, the one sample t test and the Wilcoxon rank sum tests were computed as part of Prism's Column Statistics analysis. Now, starting with Prism 8, performing one sample t tests is even easier with a separate analysis in Prism.
Steps to perform a one sample t test in Prism
- Create a Column data table.
- Enter each data set in a single Y column so all values from each group are stacked into a column. Prism will perform a one sample t test (or Wilcoxon rank sum test) on each column you enter.
- Click Analyze, look in the list of Column analyses, and choose one sample t test and Wilcoxon test.
It's that simple! Prism streamlines your t test analysis so you can make more accurate and more informed data interpretations. Start your 30-day free trial of Prism and try performing your first one sample t test in Prism.
Watch this video for a step-by-step tutorial on how to perform a t test in Prism.
We Recommend:
Article: "Choosing a Statistical Test"
Guide: "Estimation Plots" (for paired and unpaired t tests)
Guide: "Column Graphs" (for one sample, paired, and unpaired t tests)
Guide: "Normality Tests" and "QQ Plots" (for one sample and unpaired t tests)
Guide: "Nested T Test"
Guide: "Multiple T Tests" (for paired and unpaired t tests)
Analyze, graph and present your scientific work easily with GraphPad Prism. No coding required.